
1:计划
A:你们项目组芯片什么时间TO?
B:年底。
A: MPW?
B: 直接FULL MASK。
A:有钱。
B:芯片面积太大,占了6个SEAT,况且年底没有合适时间点的shuttle。老大们就直接定了FULL MASK。
A:牛X!
TAPEOUT (TO):流片,指提交最终GDSII文件给Foundry工厂做加工。
MPW :多项目晶圆,将多个使用相同工艺的集成电路设计放在同一晶圆片上流片,制造完成后,每个设计可以得到数十片芯片样品。
FULL MASK :“全掩膜”的意思,即制造流程中的全部掩膜都为某个设计服务。
Shuttle:就是MPW的时间,MPW的时间就是固定的,每个月或者每个季度有一次,有个很形象的翻译:班车,到点就走。
SEAT:一个MPW的最小面积,就类似“班车”的座位,可以选择一个或者几个座位。
简单来说,MPW就是和别的厂家共享一张掩模版,而FULL MASK则是独享一张掩膜版。
如果芯片风险比较高,则可以先做MPW,测试没有问题,再做FULL MASK。
主要的原因就是MASK(掩膜),比较贵,例如40nm的MASK大约在500万左右,而28nm的MASK大约在1000万左右,14nm的MASK大约在2500万左右。不同厂家有差异,这里只是说明MASK的成本比较高。
如果芯片失败,则MASK的钱就打水漂了。所以先做一次MPW也是分散风险的方法。
而MPW的问题就是,这个是按照面积来收钱的,例如在40nm的3mm*4mm 大约50万人民币等等。
这个叫做SEAT。一个SEAT就是3mm*4mm。
如果超过这个面积,就要额外收费。所以大芯片,是不合适做MPW的,如果是120mm2那需要10个SEAT,那么和整个MASK费用就一样了。
这种情况做MPW就不合适了,所以从成本上来说是综合考量的一件事情。
2:供应链
A:这次定了多少片WAFER?
B:24片?每片大约出1000片Die。考虑yield,大约有2万片。
A:封装怎么做?wirebonding还是flipchip。
B:Flip chip 。
A:是在foundry长好bump,还是封装厂家来长bump。
B:foundry直接长好bump送到封测厂。
A: CP和FT都做,还是只做FT。
B:yield不高,基板也很贵,只做CP的话,会浪费太多基板。
A:对对对,这个年头,基板太贵了。
B:我们老板搞到了1000万片基板。
A:牛X!
Foundry :晶圆厂,专门从事芯片制造的厂家,例如台积电(TSMC),中芯国际(SMIC),联电(UMC)。对应的就是fabless,就是设计厂家,就是没有晶圆厂。
Wafer:晶圆。
Die :晶圆切割后,单个芯片的晶圆,这个需要加上封装好的外壳才能能变成芯片。
Chip:最后封装后的芯片。

Bump :bumping指凸点。在wafer表面长出凸点(金,锡铅,无铅等等)后,(多用于倒装工艺封装上,也就是flipchip)。
Wirebonding:打线也叫Wire Bonding(压焊,也称为绑定,键合,丝焊)是指使用金属丝(金线、铝线等),利用热压或超声能源,完成固态电路内部接线的连接,即芯片与电路或引线框架之间的连接。

Flipchip:Flip chip又称倒装片,是在I/Opad上沉积锡铅球,然后将芯片翻转加热利用熔融的锡铅球与陶瓷基板相结合。
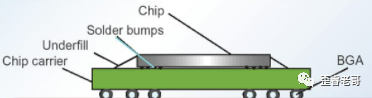
CP:直接对晶圆进行测试,英文全称Circuit Probing、Chip Probing,也称为晶圆测试,测试对象是针对整片wafer中的每一个Die,目的是确保整片wafer中的每一个Die都能基本满足器件的特征或者设计规格书,通常包括电压、电流、时序和功能的验证。可以用来检测fab厂制造的工艺水平。
FT:FT测试,英文全称FinalTest,是芯片出厂前的最后一道拦截。测试对象是针对封装好的chip,CP测试之后会进行封装,封装之后进行FT测试。可以用来检测封装厂的工艺水平。
Yield :良率,芯片的良率这个和工艺比较相关,芯片有一定几率失效,芯片越大,失效的几率也越大。
解释一下:为什么不直接做FT,而先做CP再做FT,这个是因为,CP针对晶圆,如果坏的Die就不用再去做封装了,省下封装的费用和基板的费用。
为什么不只做CP,而忽略FT,这个是因为CP测试完毕后,在封装过程中还会引入芯片失效,所以还需要做FT来将失效的芯片去掉。
这个是一个权衡的过程,如果芯片良率足够高,封装成本不敏感,CP测试省掉,直接做FT也是可以的,因为CP测试本身也是需要成本。这个就是计算良率的问题。
目前来看,芯片行业整个供应链都很紧张,所以能够抢到产能,包括抢wafer,抢基板,这些对于芯片厂商来说,都是当下的最重要的事情。
除了产能,其他都不是事!
2:IP
A:这次SOC芯片选的哪个vendor的IP?
B:S的。
A:S的据说不错,据说挺贵的,license要多少钱
B:200万刀。
A:正常价。
B:收不收loyalty。
A: 收,每个芯片额外0.5刀。
B:牛X
IP:这个对应芯片来说,就是一个完整的功能模块,
vendor :就是IP供应商,IP vendor,
license:允许使用这个IP,IP的授权
Loyalty :在用户使用这个IP后,需要按照每个芯片收钱。
SOC:片上系统,就是把CPU,总线,外设,等等放到一个芯片内部实现。例如手机处理器就是一个复杂的SOC芯片。
IP这个是构成芯片最核心的组成单元,例如USB,PCIE,CPU等等都是IP,整个芯片都是IP集成的,芯片能够做的比较复杂,核心就是IP的复用。例如那些做成几千万门,几亿门的,都是IP复用才能可以的。
如果有公司说全自主,没有用过别人的IP,这种公司要么最牛X,例如大家都知道I家,要么就是极其简单,ASIC。如果是做SOC大芯片这个领域,没有用过别家的IP,这个不太可信。例如模拟的高速serdes,PCIe,ddr,mipi等等,全部自己搞,产品周期就会很漫长。苹果的芯片也是先用了别人的IP,公司达到万亿美金产值,搞那么多人来自己搞替换。
初创公司,不用外部IP,从0开始搞,这个不是思路,是绝路。
一般是核心IP自己搞(也没有卖的),外围成熟IP有成熟就卖成熟IP,减少上市的时间,尽快迭代占了市场,逐渐核心替换,才是正常公司的思维。
千万不要被“全自研”给唬住了。
一般IP的license的费用和IP的loyalty的费用可以谈,如果量很大的话,license的费用就会比较低,loyalty的费用单片不高,但是如果量很大,最后就很可观,也有IP厂商不收license费用,最后只收loyalty的费用,这样IP厂商和芯片厂商的利益就绑在一起了。
4:技术
A: 你们项目的RTL freeze了吗?
B:freeze了,verification都差不多了。Power simlulation正在搞。
A:年底的shuttle应该没有问题吧
B:可能要delay,netlist还没有freeze
A:啥原因?
B:SDC还有点问题,后端反馈,timing没有clean;
A:那你们要抓紧了,需要去做merge,需要提前2周出gds。
B:是的,我们芯片分了10个模块单独harden,难度还是很大的。
A:牛X
RTL :register-transferlevel(RTL)是用于描述同步数字电路的硬件描述语言。
Netlist :网表,RTL需要通过综合以后才能变成网表。
SDC :设计提供约束文件,综合工具需要这个约束文件才能讲RTL转换成netlist。
SDC主要描述内容包括:芯片工作频率,芯片IO时序,设计规则,特殊路径,不用check的路径等等。
Freeze :指设计冻结,不能再改动的了,例如RTL freeze ,就是代码冻结了,netlist freeze 就是网表冻结了,不能再改了。
Verification :芯片功能验证,目前主要指芯片验证方法论(UVM),主要通过验证两者RTL和reference model是不是一致,简称A=B,见我原来写的《降低芯片流片失败风险的"七种武器"》,里面有关于验证的描述。
Simulation:仿真, 仿真通常是生成波形,一般来说,芯片的功能,verification ,芯片的功耗,可以simulation,比较直观反应真实的场景。
Hardren:指某个IP以硬模块的形式来实现。
GDS :netlist经过后端工具编程版图,而版图提交给流片厂家(foundry)的就是GDS II
Merge :就是讲单独hardren的模块,拼接进去。
merge这个是IP厂商保护IP的一种手段,一般放在foundry的专门的merge room中,才能进行。这样芯片厂商最终需要去foundry厂商那里拼接完成,得到最终的GDSII。
delay: 延期,这个次是芯片工程师最不愿意的词了,也是最经常碰到的词,一个环节不慎,就要delay,这个意味着问题出现,成本增加,周期加长。
如果芯片太大,可以把其中一部分来hardren,顶层就是几个harden模块像拼拼图一样拼起来,大型多核CPU一般都是这样做的,在版图上很容易看出来。

从上图来看,这些四四方方的位置,都是单独harden后,在芯片顶层拼起来的。
单独harden的好处是,可以多个芯片后端设计团队并行设计,大家同时设计,设计完毕,拼接一下就行。
如果有问题的话,直接改某个模块,而不用整个芯片都返工。当然,改完某个模块后,面积还要保持一致,否则就拼不进去了,改完了后,整个顶层也要重新跑一遍流程。
这个就是大芯片难度大的原因,也容易delay(延期);
大芯片的设计难度明显比小芯片设计难度大,周期也长。
大芯片类似大电影,需要大咖,大制作,灯光,道具,剧本,人员,后期,等等;小芯片类似小视频,都是芯片,其中的复杂程度,协同程度,需要人力,物力,财力都是完全不同的。
现在有个问题:大芯片赚钱,还是小芯片赚钱?
这个也不一定,你见过几亿拍的大片,没几个人看,亏得一塌糊涂,而一个人拍的小视频也可以火遍全网。
但是,大芯片是能力,国之重器,非常重要。
4:后记
上面是比较常用的一些“黑话”。
当然芯片工程师的“黑话”,远不止于此。
就像斯皮尔伯格导演《猫鼠游戏》里的莱昂纳多一样,他伪装成记者和一个资深飞行员套话,记住了这些黑话,就能伪装成一个飞行员,从而成功的登上飞机。
而知道上面这些芯片工程师的“黑话”,还远不能混为一个芯片工程师。
由于芯片分工太细,很多芯片工程师对于这些不同工序的黑话,也不能全部知道。
这个就类似我们讨论芯片的时候,芯片流程太复杂,以至于很难看清全貌。
世界已经变了。
分工越来越细,只能管中窥豹。
世界如此,芯片也如此。








暂无评论