
4、结构体成员的布局很多编译器有“使结构体字,双字或四字对齐”的选项。但是,还是需要改善结构体成员的对齐,有些编译器可能分配给结构体成员空间的顺序与他们声明的不同。但是,有些编译器并不提供这些功能,或者效果不好。所以,要在付出最少代价的情况下实现最好的结构体和结构体成员对齐,建议采取下列方法:(1)按数据类型的长度排序把结构体的成员按照它们的类型长度排序,声明成员时把长的类型放在短的前面。编译器要求把长型数据类型存放在偶数地址边界。在申明一个复杂的数据类型 (既有多字节数据又有单字节数据) 时,应该首先存放多字节数据,然后再存放单字节数据,这样可以避免内存的空洞。编译器自动地把结构的实例对齐在内存的偶数边界。(2)把结构体填充成最长类型长度的整倍数把结构体填充成最长类型长度的整倍数。照这样,如果结构体的第一个成员对齐了,所有整个结构体自然也就对齐了。下面的例子演示了如何对结构体成员进行重新排序:不好的代码,普通顺序:

推荐的代码,新的顺序并手动填充了几个字节:

这个规则同样适用于类的成员的布局。(3)按数据类型的长度排序本地变量当编译器分配给本地变量空间时,它们的顺序和它们在源代码中声明的顺序一样,和上一条规则一样,应该把长的变量放在短的变量前面。如果第一个变量对齐了,其它变量就会连续的存放,而且不用填充字节自然就会对齐。有些编译器在分配变量时不会自动改变变量顺序,有些编译器不能产生4字节对齐的栈,所以4字节可能不对齐。下面这个例子演示了本地变量声明的重新排序:不好的代码,普通顺序

推荐的代码,改进的顺序

(4)把频繁使用的指针型参数拷贝到本地变量避免在函数中频繁使用指针型参数指向的值。因为编译器不知道指针之间是否存在冲突,所以指针型参数往往不能被编译器优化。这样数据不能被存放在寄存器中,而且明显地占用了内存带宽。注意,很多编译器有“假设不冲突”优化开关(在VC里必须手动添加编译器命令行/Oa或/Ow),这允许编译器假设两个不同的指针总是有不同的内容,这样就不用把指针型参数保存到本地变量。否则,请在函数一开始把指针指向的数据保存到本地变量。如果需要的话,在函数结束前拷贝回去。不好的代码:
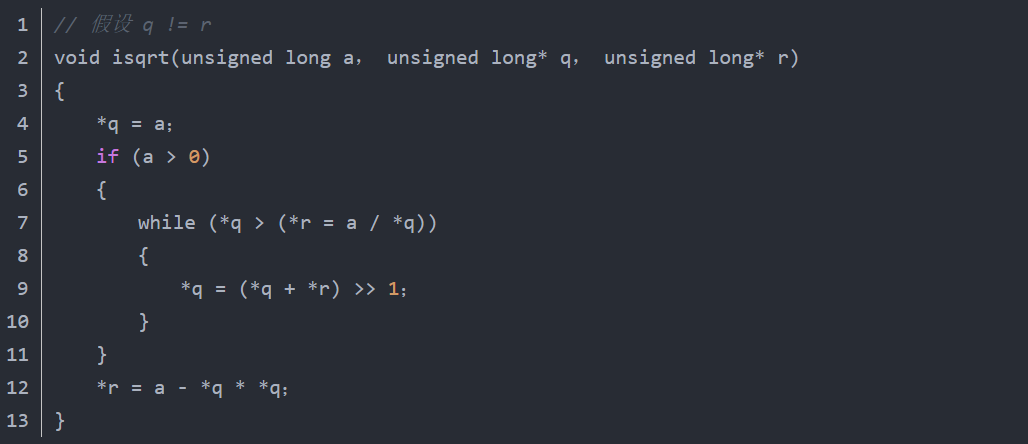
推荐的代码:
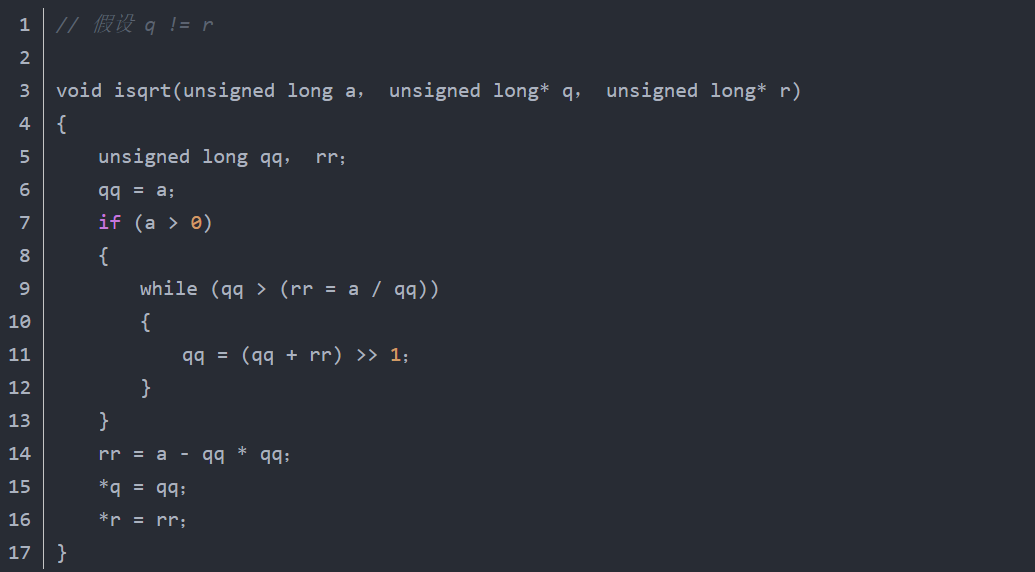
5、提高CPU的并行性(1)使用并行代码尽可能把长的有依赖的代码链分解成几个可以在流水线执行单元中并行执行的没有依赖的代码链。很多高级语言,包括C ,并不对产生的浮点表达式重新排序,因为那是一个相当复杂的过程。需要注意的是,重排序的代码和原来的代码在代码上一致并不等价于计算结果一致,因为浮点操作缺乏精确度。在一些情况下,这些优化可能导致意料之外的结果。幸运的是,在大部分情况下,最后结果可能只有最不重要的位(即最低位)是错误的。不好的代码:

推荐的代码:
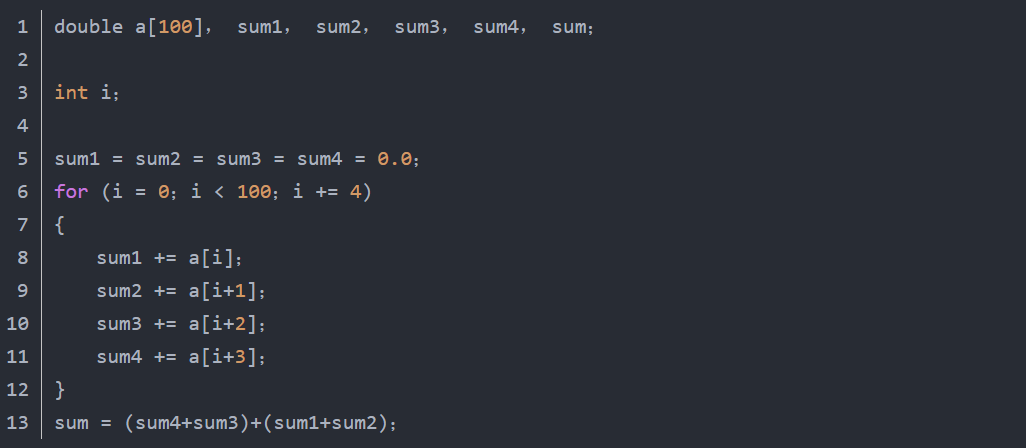
要注意的是:使用4路分解是因为这样使用了4段流水线浮点加法,浮点加法的每一个段占用一个时钟周期,保证了最大的资源利用率。(2)避免没有必要的读写依赖当数据保存到内存时存在读写依赖,即数据必须在正确写入后才能再次读取。虽然AMD Athlon等CPU有加速读写依赖延迟的硬件,允许在要保存的数据被写入内存前读取出来,但是,如果避免了读写依赖并把数据保存在内部寄存器中,速度会更快。在一段很长的又互相依赖的代码链中,避免读写依赖显得尤其重要。如果读写依赖发生在操作数组时,许多编译器不能自动优化代码以避免读写依赖。所以推荐程序员手动去消除读写依赖,举例来说,引进一个可以保存在寄存器中的临时变量。这样可以有很大的性能提升。下面一段代码是一个例子:不好的代码:
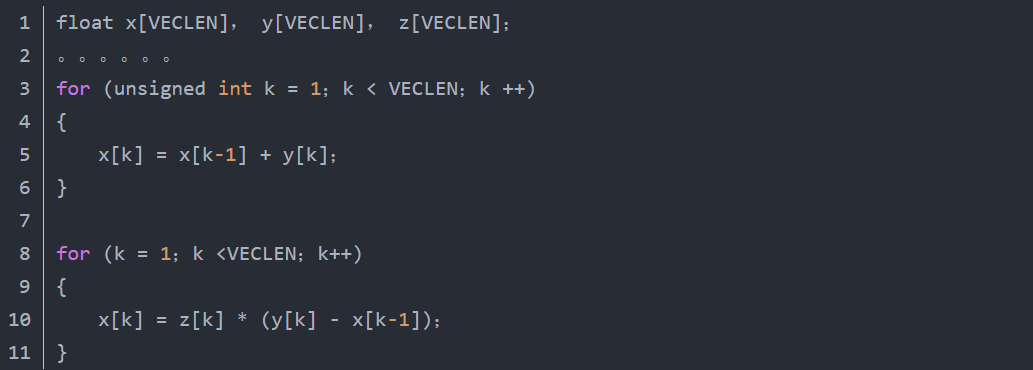
推荐的代码:










暂无评论