
1:AI芯片分类
市场上很多AI芯片,令人眼花缭乱。
根据其应用范围,大体上可以分为几类
终端AI芯片:终端AI芯片要求功耗低,算力需求也相对较低,主要是AI推理的应用。终端AI芯片以各种带AI模块的MCU来呈现,专注于某一类应用,例如,智能音箱里面的AI芯片,可以用于语音识别。智能门锁的AI芯片,可以人脸识别等等
云端AI芯片:云端AI芯片则是数据中心,用于云端AI加速,不但可以推理也可以做训练。例如NVIDLA的GPGPU卡,谷歌的TPU等等。云端AI芯片性能比较强,面积也非常大,例如A100据说在7nm下有826mm2,性能也比较强悍!
除此之外,还有边缘AI芯片。
那么边缘AI芯片是做什么来用的。
提到边缘计算,有一个非常有名的“章鱼论”。
章鱼这种生物比较奇怪,章鱼有8条腿,但是章鱼的某些决策不是都要放到大脑中来计算,而是在腿中就进行计算。
这个章鱼腿相比于章鱼大脑(云端),就是边缘端!
这个比喻非常有趣,以至于经常被边缘计算的场景来引用。
例如,自动驾驶或者ADAS (智能驾驶辅助系统),需要在本地就把整个决策及设计完成。
有很多在需要大数据量计算但是实时性比较高,不需要绕一圈到云中心来计算的场景
例如智能驾驶,智能工厂,与安防结合交通管理等等。
相对于终端AI芯片很多消费级的场景,边缘AI芯片更多的是工业领域的应用。
边缘AI基本上将应用局限在某个范围内,可以是一辆汽车,一列火车,一个工厂,一个商店。
在这个范围内,有一些实时的AI决策及处理需求需要被满足。
相应的我们会把AI赋能称之为,自动驾驶,智能制造,智慧零售等等。
其核心目的主要强调在数据来源侧来解决问题。
这就是边缘AI芯片存在的需求。
2:边缘AI芯片特征
那么边缘AI芯片都有什么特征?
1:算力强:边缘AI的算力要比终端要算力更强,通常都是独立解决问题。但是性能要比小区的人脸识别或者智能音箱这种语音识别的基于某种应用的端侧AI芯片的处理能力要强1-2个数量级。
2:外设丰富:边缘AI基本上强调信息的可获得性,例如多路摄像头的输入的需求,对于类似MIPI的接口的数量会有很大的需求,例如可以同时支持多路摄像头等视频音频的输入。
3:可编程性:边缘AI芯片通常用面向工业用户,需要AI赋能用户,换言之:AI要和用户应用场景相结合,通常根据不同工业用户不同的场景需要进行编程,用于适配不同的模型和场景。也不局限于某种应用。
一个良好的可编程的架构是解决问题的关键。边缘AI芯片不是直接给工业客户用,而是要根据工业客户的需求进行客户需求AI赋能,这个是边缘AI芯片核心特征。
3:边缘AI芯片架构
那么边缘AI芯片的架构是什么样子的?
举个例子,边缘AI计算平台,JESTON 应该算是一个。
其最新一代发布的是JESTON AGX Orin 。
JETSON作为英伟达边缘的AI计算平台,其名气没有英伟达的GPGPU大。
但是,JESTON同时继承了Ampere的架构的GPGPU和 ARM Cortex-A78,在边缘侧AI芯片中,既可以做推理也可以做训练。
作为一个边缘AI产品,其有200Tops的处理性能(INT8)。
我们以JESTON AGX Orin为例,探索下其芯片内部架构是怎样的。
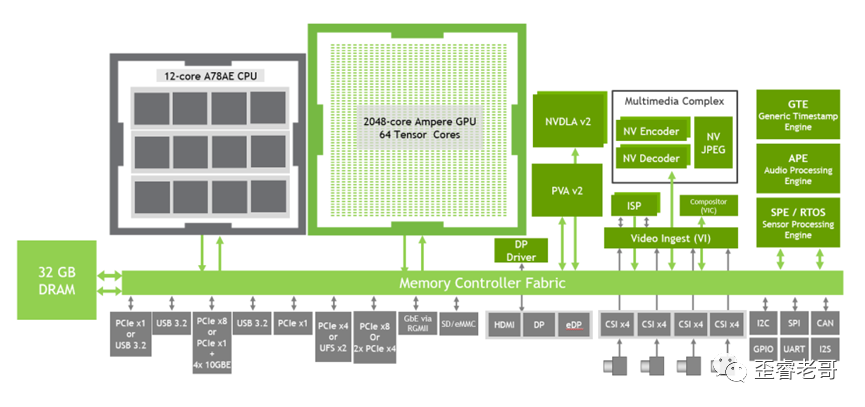
这个芯片的计算部分主要是三大件:CPU,GPU,DSA(NVDLA+PVA)
CPU:
JESTON其内部有3组4核的A78,频率可以到2Ghz。也就是说,这个芯片内部有12核的A78的处理器,不同于手机的处理器,3个cluster的A78是对称的,不是手机处理器的大小核设计,其主要是面向计算服务,而不是手机应用中不同负载的低功耗。在一些标量的运算中,多核A78的计算能力也是非常强悍。

GPU:
GPU是英伟达最新的安培架构,拥有2048个CUDA核,以及64个Tensor内核。这些都可以可编程的。安培架构是最新一代的GPGPU架构,前面几代分别是:Kepler,Maxwell,Pascal, Volta等。最新一代的安培架构升级了tensor core。用了安培GPU以后,与其他边缘AI芯片不同的是,可以支持推理和训练。
最重要的是,这个AI芯片可以用cuda来编程了,而可编程性则是边缘AI芯片的核心需求了。
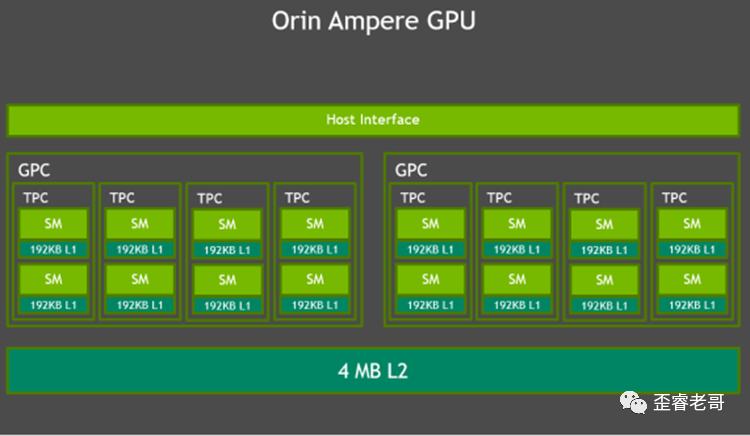
DSA:
作为AI加速单元,JESTON本身也有另外还有2个NVDLA 的硬核,以及VISION加速器 PVA;
NVDLA主要用于推理。内核核心还是一个大的矩阵卷积运算。
其中NVDLA已经开源,有兴趣的小伙伴可以在GITHUB上下载并运行这些源码。详见:nvdla· GitHub
这个可以可看到工业界的实际在用的成果开源,也对业界有很大的促进作用。
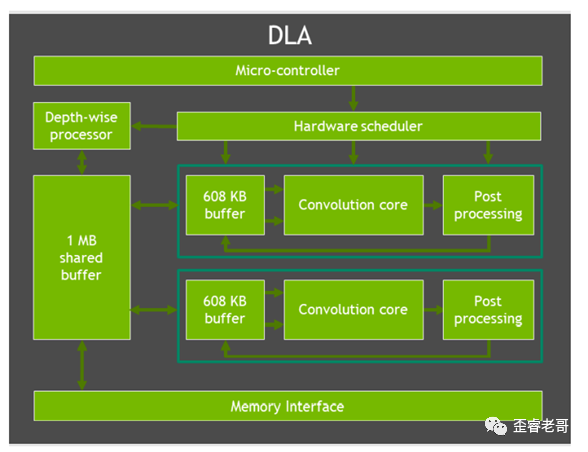
PVA用了VPU的架构,使用VLIW的架构,VLIW是超长指令字结构,其并行度比较好,VIEW架构设计简化了硬件结构,其二,VLIW的大位宽执行并不会以牺牲性能和频率为代价。但是同时将问题交给了软件来运行。
IO资源:
除了计算资源,IO资源也比较丰富,毕竟边缘AI侧,就需要的丰富的输入,支持6个摄像头以及16组通道的MIPI接口。
如果边缘AI芯片选一个重要的接口,那肯定是MIPI了,毕竟,边缘AI芯片,除了算力之外,还缺少不了的就是MIPI接口。
MIPI就是边缘AI芯片的眼睛,(用于连接摄像头)。毕竟和人不同,需要很多双眼睛,毕竟边缘AI芯片需要“眼观六路,耳听八方”。
只有大脑,没有耳朵和眼睛,边缘AI芯片是不能工作的。
同样还有USB接口,也可以支持一些USB摄像头。
同样可以支持PCIe。RC和EP都支持,也就是说,可以同时作为加速卡插在别的主机上,也可以作为主设备插别的加速卡。
同时在网络方面,支持4路10G口,可以实现高速互联,如果有需要可以实现高速网络传输,或者几个JESTON AGX的互联。
下图就是 JESTON AGX Orin 的详细参数,拿走不谢!
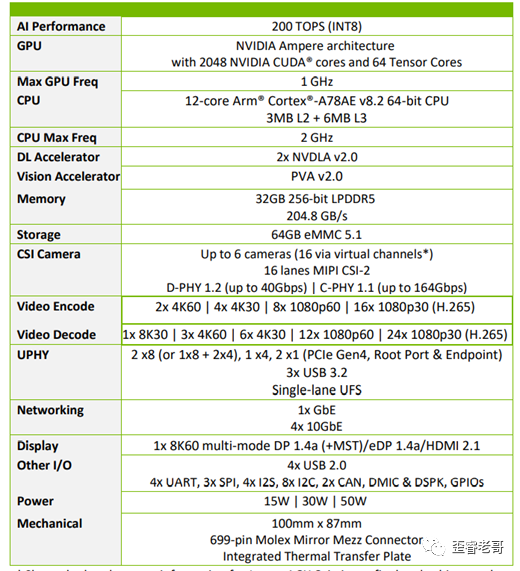
根据这些参数,芯片面积小不了,我觉得这颗芯片可能是7nm的制程。才能在面积和功耗上比较平衡一下。
其典型功耗大约在15W,30W,45W几个不同的量级上。
4:边缘AI芯片作用
那么这么强悍性能的AI芯片能做什么?
举个例子,现在疫情下,很多场所都有人流的限制(本场所限流100人!)。
小到一个商店,大到一个街区。适时获取人流就是一个典型的任务。
通过人像识别,获取一个区域内的人流的密度,实时决定对区域内人流进行管控。
如果是终端的AI的MCU,很难有很大的算力,也不同时接受多路视频的输入。
那边缘端AI芯片就有了用武之地。
作为一个方案商,不但要有一个非常强劲的AI引擎,其次要有很多的视频输入源。
最后要通过一个非常强悍的AI框架(SDK)将这些硬件运行起来。
也就是说边缘AI需要根据用户对于AI的需求二次开发。
刚才提到,边缘AI其中一个重要的特征就是,根据工业场景进行AI+场景的再开发。
很多AI芯片纸面性能很强,但是如何将这些算力转换成用户感知的提升,这个里面就有很多内功可做。
因此工业用户需要的是一个开放AI平台,而不是一个只有算力的芯片,更重要的是要根据用户需求进行AI业务开发。
有句古话“干活不由东,累死也无功”。
只有硬件,没有软件,或者软件不好用,就好比武功只有一身招式,没有内功心法一样。
AI芯片算力虽强,没有软件(SDK)也发挥不出来。
软硬兼修是永远不过时的选择。
如何将AI算力转换成用户生产力。
在这个方面,Jeston AGX Orin提供了jetpack 5.0,支持了cuda11和最新版本的cuDNN和tensorRT。
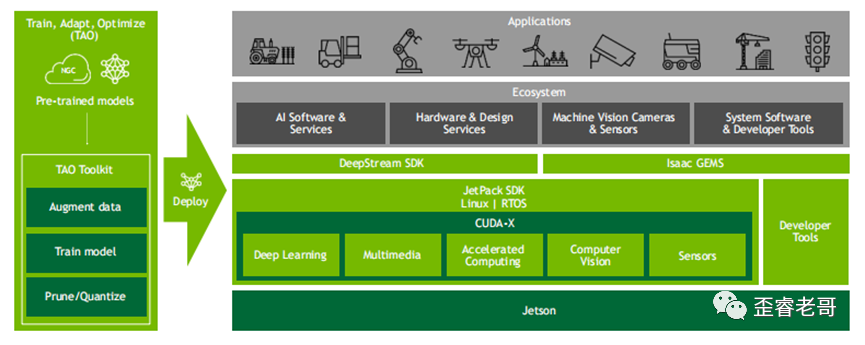
通过这些软件工作,特别是CUDA,这些利于用户开发的工具将JESTON平台上强悍的算力和丰富IO结合起来。
最终完成边缘计算赋予AI芯片的“使命任务”。
最终用户得到的是:用户定义的AI芯片。
或者说是需求定义的AI芯片。
这才是边缘AI芯片的本质!










暂无评论