
GPU可以用于图形渲染,GPU 作为加速图形绘制的芯片时,它主要面向的产品主要是会集中在 PC 和游戏两个市场。也能够用于高性能计算领域(GPGPU)和编解码场景(子模块)等。
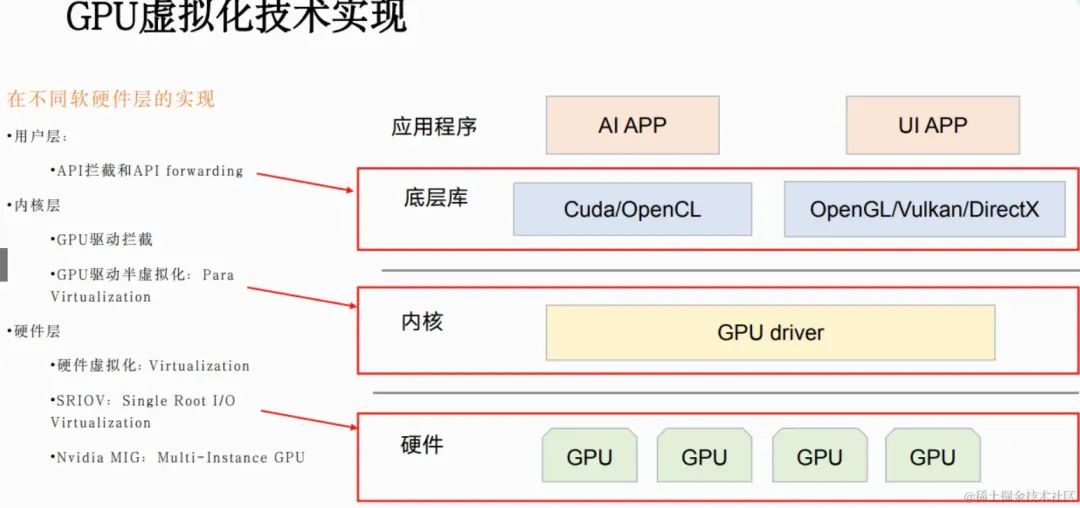
GPU虚拟化实现
为什么需要GPU虚拟化:
资源共享:GPU性能过强,资源浪费
资源隔离:显存,算力隔离
隔离场景:容器、虚机
应用场景:虚拟桌面、渲染、AI计算
用户层虚拟化
本地API拦截和APIforwarding
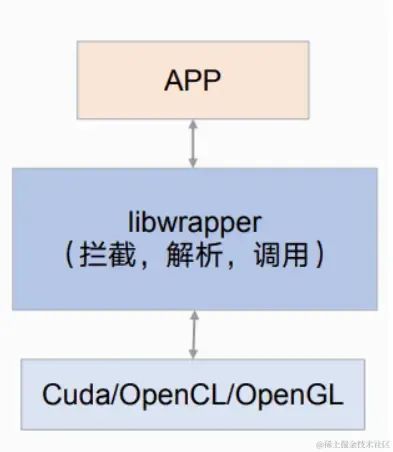
在用户态实现一个函数,然后实现底层库的所有API
libwarapper拦截所有函数调用,然后对参数进行解析,然后用参数去调用实际的底层库,然后把结果返回给APP。(编译器可以使用静态或者动态链接)
静态链接(Static Linking) 程序所依赖的库和模块会在编译和链接时直接复制到可执行文件的二进制代码中。这样生成的可执行文件体积比较大,但运行时不需要外部的共享库。
动态链接(Dynamic Linking) 程序所依赖的库和模块不会被复制到可执行文件中,而是在编译时只 embed 引用路径。运行时通过这些路径引用(linking)外部的共享库文件。这样生成的可执行文件体积比较小,但需要外部的共享库支持。
远程API forwarding

可以实现 GPU 池化:即多个 GPU 可以组成调用池,由多个 client 来调用,可以做到让不具备 GPU 的机器能实现 GPU 的功能。
传输过程中可能需要进行序列化和反序列化
远程API调用(Remote API Forwarding)的一般过程是:
客服端程序(虚拟机中的应用程序)通过特定语言(如REST)调用预定义的API接口。
调用请求送到客服端操作系统的接口模块。
接口模块将请求进行封装编码,通过网络发送给虚拟化管理程序。
虚拟化管理程序(通常在服务端)接收请求,解析请求参数,执行相应动作。
执行完成后,虚拟化管理程序将结果编码封装成应答包。
将应答包通过网络发送给客服端操作系统。
接口模块在客服端操作系统接收到应答包,进行解码解析。
将执行结果返回给发起调用的客服端应用程序。
这样通过网络进行编码解码、传输的调用请求与应答,构成了客服端应用程序与服务端虚拟化管理程序之间的远程API调用机制。
相比半虚拟化,远程API调用增加了网络通信的开销,但是对客服端操作系统无需修改,更易实现与语言无关的访问接口。两者各有优劣。
半虚拟API forwarding

APP 和 libwrapper 运行在虚机中;
在虚机内核里面要实现virtio的前端
host端需要实现virtio的后端
通过这两个前后端进行通信,然后由host端调用真实的功能
virtio通过共享内存的方式在guest和host端共享数据,减少了数据拷贝
运行过程:
客服端操作系统(Guest OS)通过特定的指令或者函数调用发起对虚拟化层的请求。这些特定的调用就是半虚拟化API,如hypercall、VMCALL等。
这些半虚拟化API调用会被客服端OS中的接口层(Paravirtualized Interface Layer)拦截。接口层预先定义了这些调用和参数之间的映射关系。
接口层将获取到的来自客服端OS的请求参数,根据事先定义的映射协议,翻译并封装为hypervisor可以识别的格式。
然后调用vminstruction等机制,触发VMexit或异常,将请求发送给底层的虚拟机监控器(VMM)或者hypervisor。
hypervisor接收到请求后,解析请求参数,执行相应的操作,并返回响应结果。
接口层再次拦截返回结果,并根据映射关系翻译成客服端OS可以识别的格式。
最后将结果返回给发起请求的客服端OS或应用程序。
通过这种协作的流程,实现了在不完全模拟硬件的情况下,使客服端OS可以与虚拟化层进行交互和请求处理。从而获得较高的执行效率。
hypervisor,也称为虚拟机监控器(VMM),运行在host端,即物理服务器上。它允许在一台物理机器上运行多个虚拟机,实现硬件资源的虚拟化和分配。
具体来说,hypervisor的位置是在硬件和guest操作系统之间,它直接在物理服务器硬件上运行。针对不同类型的虚拟化技术,hypervisor的实现方式会有所不同:
在完全虚拟化(Full Virtualization)中,hypervisor实现了对处理器、内存和设备的模拟,用于为上层的guest操作系统提供一个完全虚拟化的平台。
在像KVM这种基于主机的虚拟化(Hosted Hypervisor)中,hypervisor运行在主机操作系统内核中,利用内核的虚拟化特性。
在半虚拟化(ParaVirtualization)技术下,hypervisor与guest操作系统通过预定义的虚拟化API进行交互。
而对于像Docker这样的容器虚拟化,其底层也依赖于主机的hypervisor或容器引擎来进行资源分配、隔离等。
所以,总的来说,hypervisor属于虚拟化层,运行在物理主机端,用于管理虚拟机以及与之对接的硬件资源。它在客服端操作系统之下,主机硬件之上。
半虚拟化 vs 远程API调用
| 半虚拟化 | 远程forwarding | |
实现位置不同 | 接口实现在guest操作系统内核,本地接口 | 通过网络实现guestOS与虚拟化管理程序之间的通信 |
接口位置不同 | 半虚拟化与guestOS紧密相关 | 无关 |
性能差异 | 接口响应更快,无网络开销 | 网络通信 |
兼容性不同 | 需要修改guest端OS来实现接口 | 无需对guest端进行更改,更方便迁移 |
使用范围不同 | 系统级交互 | 用户交互 |
内核层虚拟化
正常驱动方式:app调用底层库,底层库调用驱动,驱动调用硬件。其中底层库与驱动是通过设备文件来访问的,因此拦截的关键点是设备文件。
内核层GPU驱动拦截:实现一个内存拦截模块,他是运行在driver上面 。就是拦截了app到底层driver的调用。
正常驱动方式是app调用底层库,底层库调用驱动,驱动调用硬件。其中底层库与驱动是通过设备文件来访问的,因此拦截的关键点是设备文件。

内核拦截模块实际调用driver
返回的时候内核拦截模块在进行解析
拦截的不是API,拦截的是系统调用,因此需要了解底层库调用GPU驱动的系统调用的含义(需要文档或者逆向)
适合容器应用,不适合虚机,因为容器共享宿主操作系统的内核,而虚拟机通常运行独立的操作系统内核。在虚拟机中,由于每个虚拟机都有自己的内核,GPU驱动拦截可能需要更多的复杂性和性能开销。容器中的内核共享可以简化GPU驱动的管理和性能优化
内核拦截模块只需要拦截必要的系统调用(想做显存隔离就只拦截分配和释放显存的调用,算力就找算力调用)
内核层GPU半虚拟化(虚机场景)
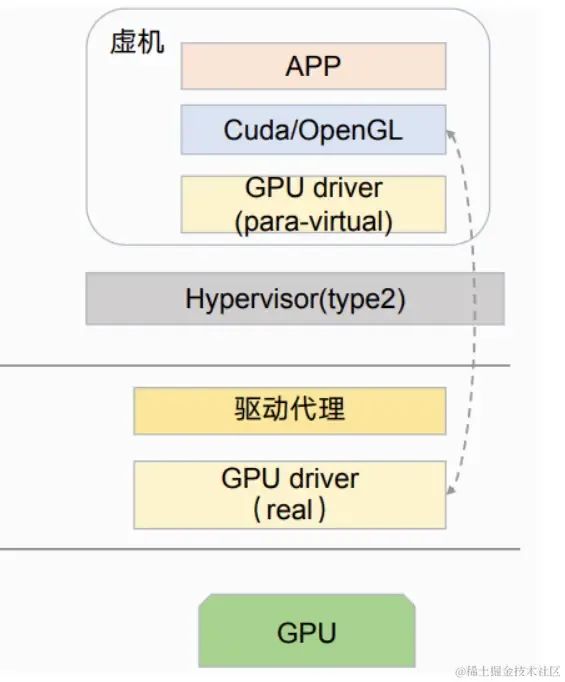
正常调用结果是虚机内到GPUDriver,由于无法直接接触硬件,因此需要通过从guest切换到远程/本地的hypervisor,然后通过驱动代理访问真实的Driver,
APP 和底层库都在 VM 里;
结合硬件虚拟化支持类似 vGPU 功能
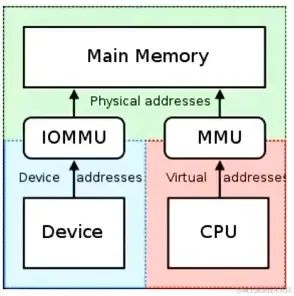
GPU硬件虚拟化 1、硬件虚拟化基础:CPU硬件虚拟化、IOMMU
2、全虚拟化/透传GPU
GPUDriver不需要做任何修改。GPU直接透传给虚机,性能损耗最小;相当于把整块GPU给虚机,无法实现GPU资源共享,不属于GPU虚拟化。
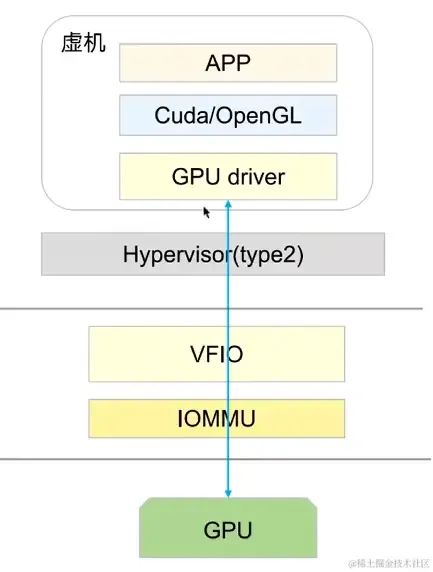
3、NVIDIA vGPU(软件切分)
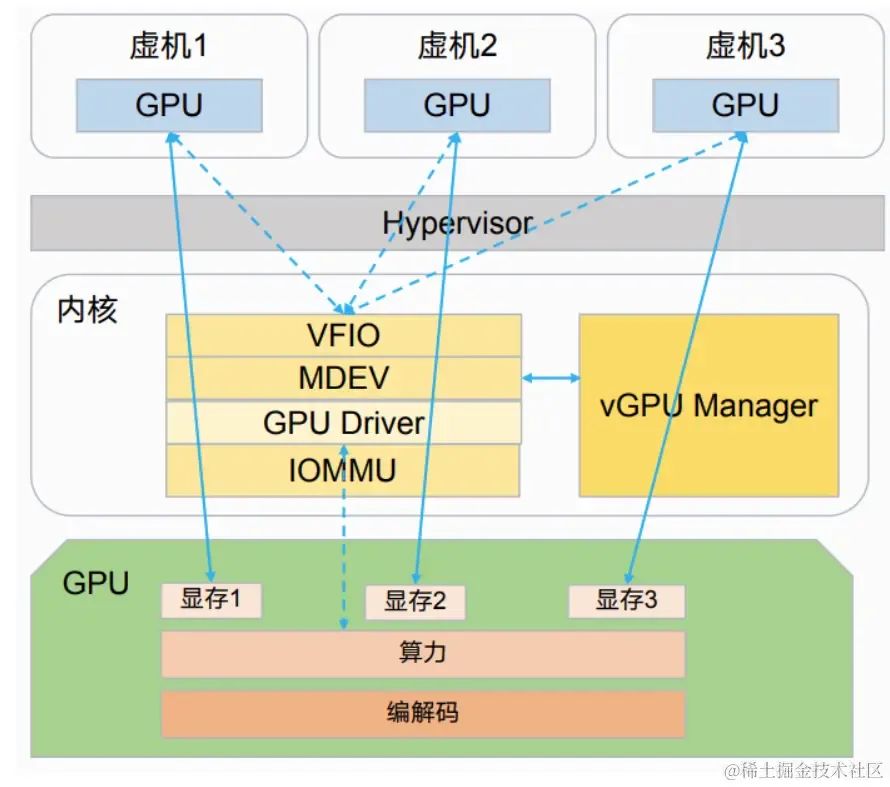
通过内核层虚拟化,独享的,算力是时间片全部占用
中间过程较多,损耗比较大,软件收费
其中显存是固定切分的
4、NVIDIA MIG(硬件切分)
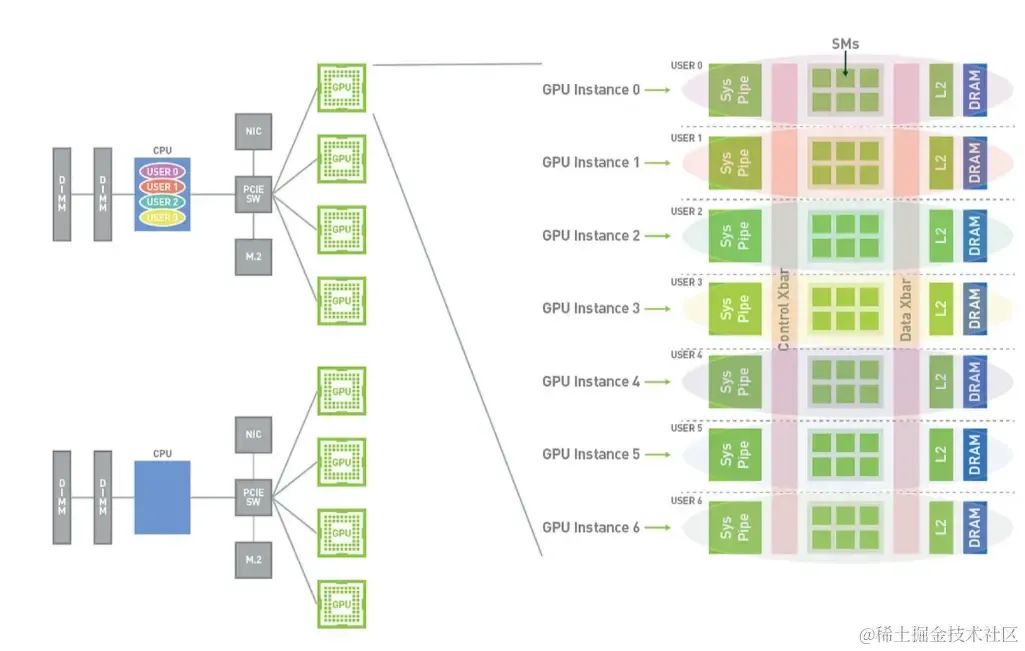
可以直接把 GPU 切分多分,每一份资源硬件隔离;
每一 MIG 的切分,可以当作一个 GPU 来使用,同时可以结合容器来部署
5、NVIDIA MIG vGPU
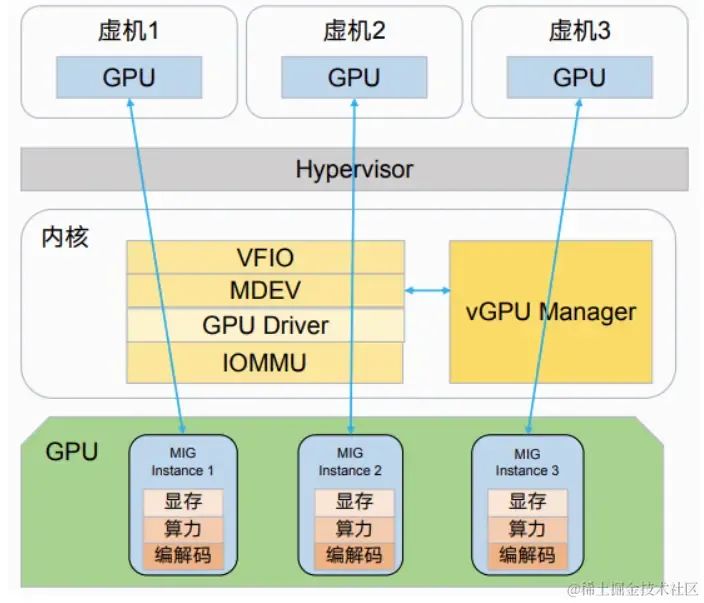
算力,显存都直接按照MIG进行硬件切分然后分配给VM
MIG直接将MIG实例分配给用户,MIG vGPU则引入了虚拟化软件层,允许多个虚拟机共享同一GPU,提供了更大的灵活性,但是也需要额外的开销
6、AMD MxGPU
通过SRIOV的方式将GPU切分为PF(Physical Function)和VF(Virtual Function)。
PF(Physical Function):
PF 是硬件设备的实际物理功能。对于网络适配器,PF 通常是指整个物理网卡的功能,而对于 GPU,PF 则是指整个物理显卡的功能。
PF 负责直接与物理硬件进行通信,控制设备的实际硬件资源,如网络适配器的端口、传输协议、GPU 的计算单元等。
在虚拟化环境中,PF 通常由虚拟化管理程序(如 Hypervisor)直接控制,而不是被分配给虚拟机使用。
VF(Virtual Function):
VF 是对 PF 的虚拟划分,它是 PF 的一个逻辑部分。VF 允许将单个物理设备虚拟化为多个逻辑设备,以便在多个虚拟机之间共享物理设备。
每个 VF 具有自己的配置信息、MAC 地址、虚拟资源等。VF 可以被分配给虚拟机,使虚拟机能够直接访问部分物理设备的功能,而不需要通过 PF 进行中介。
VF 的创建和配置通常由虚拟化管理程序完成,虚拟机可以像访问独立的物理设备一样访问 VF。
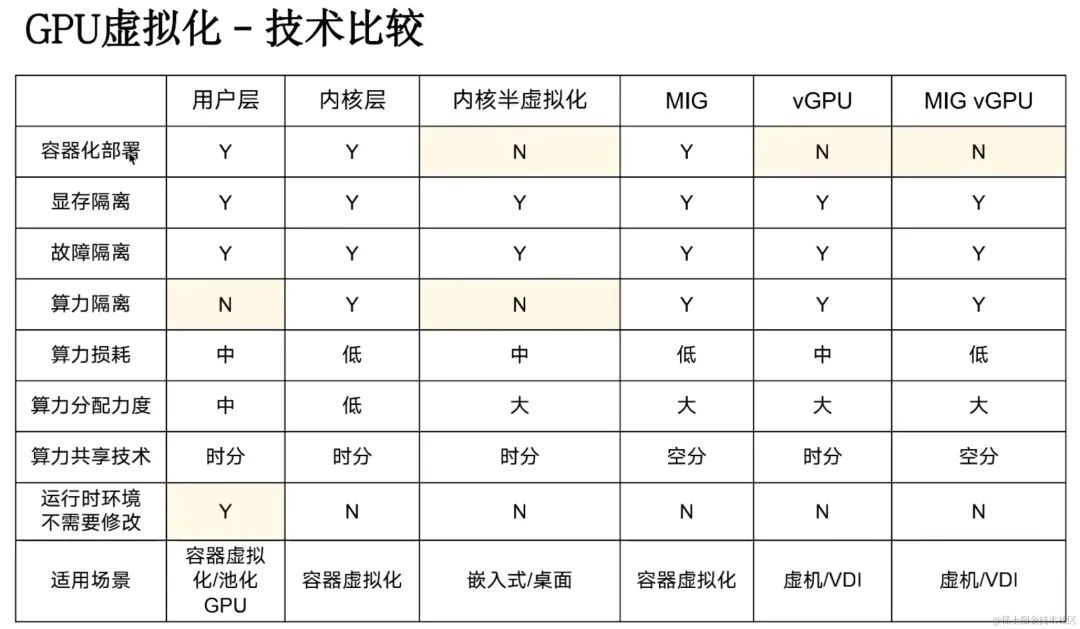
GPU虚拟化技术比较







暂无评论