
导致AI“智障”的问题竟是内存?
能(AI)怀疑论者批评当前技术中存在的内存瓶颈,认为无法加速处理器和内存之间的数据传输,从而阻碍了实际应用的推广。
用于在数据中心训练AI模型的AI加速器需要最高的可用内存带宽。虽然将整个模型存储在处理器中,可以省掉片外存储器,但这不是一个可行的解决方案,因为最大的模型需要测量的参数达数十亿或数万亿个。
过去的系统受内存的限制,而如今的数据中心架构则利用各种技术来克服内存瓶颈。
高带宽内存
一种流行的解决方案是利用高带宽内存(HBM),其中包括通过硅中介层将4、8或12个DRAM裸片的3D堆栈连接到处理器。该技术的最新版本HBM2E具有比其前身更快的每引脚信号速率,高达每引脚3.6Gb/s,因而提高了带宽。三星和SK Hynix都能提供8裸片HBM2E堆栈,其总容量为16GB,带宽高达460GB/s(SK Hynix表示,相比之下DDR5带宽为2.4GB/s,GDDR6为64GB/s)。HBM3有望将速度和容量提得更高。
最新版本的英伟达旗舰数据中心GPU A100可以提供80GB的HBM2E性能和2TB/s的内存带宽。A100包含5个16GB DRAM堆栈,加上利用HBM2的40GB版本DRAM,总带宽可达1.6TB/s。两者之间的差异将用于极度消耗内存的深度学习推荐的AI模型训练速度提高了三倍。
同时,数据中心CPU也在充分利用HBM带宽。英特尔的下一代Xeon数据中心CPU Sapphire Rapids也将HBM引入了Xeon系列。它们是英特尔首款新AMX指令扩展的数据中心CPU,专为AI等矩阵乘法负载设计。他们还可以利用片外DDR5 DRAM或DRAM加HBM。“通常情况下,CPU针对容量进行了优化,而加速器和GPU针对带宽进行了优化,”英特尔高级首席工程师Arijit Biswas在最近的一次Hot Chips演讲上介绍道。“然而,随着模型大小呈指数级增长,我们看到对容量和带宽的需求一直在持续增长。Sapphire Rapids通过原生支持这两者来做到这一点。”

图1:英伟达的A100数据中心GPU具有6个HBM2E内存堆栈(出于良率原因仅利用了五个)(来源:Nvidia)
该方法通过内存堆叠得到了增强,“其中包括对软件可见的HBM和DDR的支持,以及将HBM用作DDR支持缓存的软件透明缓存,”Biswas补充道。
然而,Sapphire Rapids的首席工程师Nevine Nassif告诉电子工程专辑,HBM版本是以牺牲芯片面积为代价的。
“[与HBM兼容的]裸片略有不同,”她说,“还有一个不同于DDR5控制器的HBM控制器。在没有HBM的Sapphire Rapids版本中,我们往裸片的一个区域中添加了用于加密、压缩等的加速器。所有这些都省掉了——除了数据流加速器——取而代之的是HBM控制器。”
“最重要的是,为了支持HBM的带宽要求,我们必须对网格进行一些更改。”Nassif补充道。
除了CPU和GPU,HBM在数据中心FPGA中也很受欢迎。例如,英特尔的Stratix和赛灵思Versal FPGA都有HBM版本,一些AI ASIC也采用它。腾讯支持的数据中心AI ASIC开发商Enflame Technology将HBM用于其DTU 1.0器件,该器件还针对云AI训练进行了优化。这款80-TFLOPS(FP16/BF16)芯片利用了2个HBM2堆栈,可提供通过片上网络连接的512-GB/s带宽。

图2:DTU 1.0数据中心AI加速芯片有2个HBM2内存堆栈。(来源:Enflame科技)
单位成本性能
虽然HBM为数据中心AI加速器所需的片外内存提供了极高的带宽,但仍然存在一些值得注意的问题。

图3:Graphcore对不同内存技术的容量和带宽进行了比较。当其他人尝试利用HBM2E解决这两个问题时,Graphcore却在其Colossus Mk2 AI加速器芯片上利用了主机DDR内存和片上SRAM的组合。(来源:Graphcore)
Graphcore就是其中之一。Graphcore首席技术官Simon Knowles在Hot Chips演讲中指出,大型AI模型中更快的计算需要相应的内存容量和带宽。虽然许多人利用HBM来提高容量和带宽,但权衡因素还包括HBM的成本、功耗和热限制。
Graphcore的第二代智能处理单元(IPU)相反利用其大型896 MiB片上SRAM来支持其1,472个处理器内核运行所需的内存带宽。Knowles表示,这足以避免卸载DRAM所需的更高带宽。为了支持内存容量,因太大而无法在芯片上安装的AI模型利用服务器级DDR形式的低带宽远程DRAM。这种配置连接到主机处理器,允许中等规模模型扩展分布在IPU集群中的SRAM上。
鉴于该公司以单位成本性能为基础推广其IPU,Graphcore拒绝HBM的主要原因似乎是成本。
“HBM与AI处理器集成的净成本是服务器级DDR每字节成本的10倍以上,”Knowles指出。“即使容量适中,HBM也主导着处理器模块的成本。如果AI计算机可以利用DDR,那么它就可以在相同的拥有成本下部署更多的AI处理器。”
Knowles认为,40GB的HBM有效地将封装后的标线大小处理器的成本提高了三倍。Graphcore的8GB HBM2与8GB DDR4的成本细分估计表明,HBM裸片的尺寸是DDR4裸片的两倍(将20-nm HBM与Knowles认为是同时代的18-nm DDR4进行比较),从而增加了制造成本。还有TSV蚀刻、堆叠、组装和封装的成本,以及内存和处理器制造商的利润率。
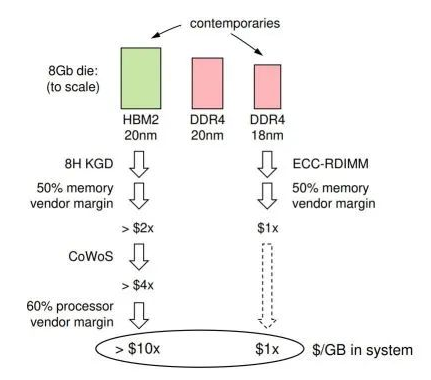
图4:Graphcore对HBM2与DDR4内存的成本分析显示,前者的成本比后者高10倍。(来源:Graphcore)
“DDR DIMM不会发生这种边际堆叠,因为用户可以直接从内存制造商处采购,”Knowles表示。“事实上,出现可插拔式计算机组件生态系统的一个主要原因是为了避免边际堆叠。”
走得更远
脱胎于Hot Chips的隐形模式,EsperantoTechnologies提供了另一种解决内存瓶颈问题的方法。该公司的1,000核RISC-V AI加速器针对的是超大规模推荐模型推理,而不是上面提到的AI训练负载。
Esperanto公司创始人兼执行主席戴夫·迪策尔指出,数据中心推理不需要巨大的片上内存。“我们的客户不想要250MB的片上内存,”Ditzel说。“他们想要100MB——他们想用推理做的所有事情都适配100MB。比这更大的任何东西会需要更多内存。”
Ditzel补充说,客户更喜欢将大量DRAM与处理器放在同一张卡上,而不是在芯片上。“他们建议我们,‘只需将所有内容都放到卡上,然后利用您的快速接口。然后,只要你能以比PCIe总线更快的速度达到100GB的内存就行了。’”
Ditzel将Esperanto的方法与其他数据中心推理加速器进行比较后发现,其他人专注于消耗整个功率预算的单个巨型处理器。这家初创公司坚称,Esperanto的方法——将多个低功耗处理器安装在双路M.2加速卡上——可以更好地利用片外内存。单芯片竞争对手“引脚数量非常有限,因此他们必须利用像HBM之类的产品才能在少量引脚上获得非常高的带宽——但HBM确实很昂贵、很难获得而且功耗很高,”Ditzel表示。
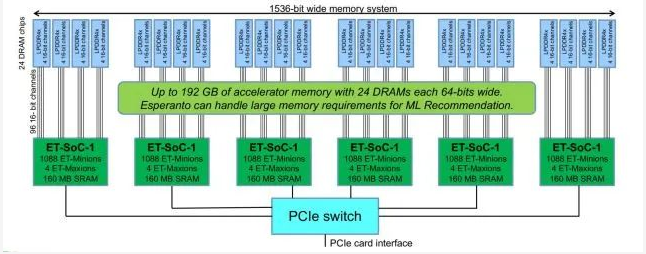
图5:Esperanto声称通过利用6个较小的芯片而不是单个大芯片解决了内存瓶颈问题,并留出了引脚用于连接LPDDR4x芯片。(来源:世界语技术)
Esperanto公司的多芯片方法可提供更多引脚用于与片外DRAM通信。除了6个处理器芯片外,该公司还利用了24个专为手机设计的低压廉价LPDDR4x DRAM芯片,“每比特能量与HBM大致相同”,Ditzel指出。
“因为[LPDDR4x]的带宽[比HBM]低,所以我们可以通过更宽尺寸来获得更多带宽,”他补充道,“我们在加速卡的内存系统上利用1,500位宽,[而单芯片竞争对手]负担不起1,500位宽的内存系统,因为对于每个数据引脚来说,你必须有多个电源和多个接地引脚,引脚实在太多了。
“之前处理过这个问题,我们只好说,‘让我们把它分开吧,’”Ditzel透露。
通过822-GB/s的内存带宽访问192GB的总内存容量。所有64位DRAM芯片的总和可得到1,536位宽的内存系统,分成96个16位通道以便更好地处理内存延时。这一切都满足120W的功率预算。
流水线权重
晶圆级AI加速器公司Cerebras Systems设计了一个处于晶圆远端的内存瓶颈解决方案。在Hot Chips上,该公司发布了一款用于其CS-2AI加速器系统的内存扩展系统MemoryX,旨在实现高性能计算和科学工作负载。MemoryX力图训练带一万亿或更多参数的大型AI模型。

图6:Cerebras Systems公司的MemoryX是其CS-2晶圆级引擎系统的片外存储器扩展,其行为就像在片上一样。(来源:Cerebras系统)
MemoryX是DRAM和闪存的组合,其行为就像片上一样。该架构被宣传为极具弹性,设计可容纳4TB到2.4PB(2000亿到120万亿个参数)——该容量足以容纳世界上最大的AI模型。
该公司的联合创始人兼首席硬件架构师Sean Lie表示,为了使其片外内存表现得像片上一样,Cerebras优化了MemoryX,以消除延时影响的方式将参数和权重数据以流的形式传输给处理器。
“我们将内存与计算分开,从根本上使它们脱离开来,”他说,“这样做能使通信变得优雅而直接。我们可以这样做的原因是神经网络针对模型的不同组件利用不同的内存。因此,我们可以为每种类型的内存和每种类型的计算设计一个专门构建的解决方案。”
最终这些组件被解开,从而“简化了缩放问题,”Lie说。
在训练期间,必须立即访问对延时敏感的活动内存。因此Cerebras会保持激活片上内存。
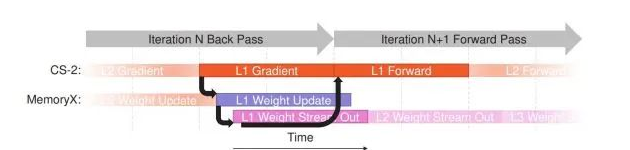
图7:Cerebras在AI训练期间利用流水线消除延时敏感的传递信息。(来源:Cerebras系统)
Cerebras将权重存储在MemoryX上,然后根据需要将它们流式传输到芯片上。Lie表示,在没有背靠背依赖性的情况下,权重内存的利用相对较少。这可以用来避免延时和性能瓶颈。粗粒度流水线还避免了层之间的依赖关系;层的权重在前一层完成之前开始流式传输。
同时,细粒度流水线避免了训练迭代之间的依赖关系;后向传播中的权重更新被同一层的后续前向传播所覆盖。
“通过利用这些流水线技术,权重流水式执行模型可以隐藏外部权重引起的额外延时,并且可以达到如同权重在晶圆上[被本地访问]时的相同性能,”Lie表示。









暂无评论